LangExtract
LangExtract: Gemini-powered Information Extraction Library
LangExtract is a powerful Python library for extracting structured information from unstructured text using LLMs. Experience LangExtract's precise source grounding and interactive visualization capabilities.
LangExtract Key Features
LangExtract Precise Source Grounding
LangExtract maps every extraction to its exact location in the source text, enabling visual highlighting for easy traceability and verification.
LangExtract Reliable Structured Outputs
LangExtract enforces a consistent output schema based on your few-shot examples, leveraging controlled generation in supported models like Gemini.
LangExtract Long Document Optimization
LangExtract overcomes the 'needle-in-a-haystack' challenge using optimized text chunking, parallel processing, and multiple passes for higher recall.
LangExtract Domain Adaptability
LangExtract allows you to define extraction tasks for any domain using just a few examples. LangExtract adapts to your needs without requiring model fine-tuning.
LangExtract Interactive Visualization
LangExtract generates interactive HTML visualizations to review extracted entities in context with intuitive highlighting.
LangExtract Open Source
LangExtract is free to use under Apache 2.0 License. Community-driven LangExtract development with full transparency.
LangExtract Applications
LangExtract for Healthcare
Use LangExtract to extract key information from clinical notes and medical reports while maintaining source traceability.
LangExtract for Legal Documents
LangExtract helps extract clauses, dates, parties and other information from contracts and legal documents.
LangExtract for Research & Analysis
LangExtract enables you to analyze literature, extract entities from academic papers, and structure unorganized text data.
LangExtract for Business Intelligence
Transform business documents into structured data using LangExtract for analysis and decision-making.
What Developers Are Saying About LangExtract
The developer community has shown tremendous excitement and positive response to LangExtract across all use cases
AI Transparency & Traceability
Transforming language into structured gold with unprecedented AI transparency and traceability potential.
Future of Data Science
A huge step forward for the future of data science, enabling structured data extraction from complex documents.
Developer Productivity
Extremely useful across all development projects, significantly improving workflow efficiency.
Global Impact
Receiving attention worldwide, including strong interest from international developer communities.
Key LangExtract Benefits Highlighted by Community
LangExtract is excellent for processing medical reports and clinical documentation
LangExtract is perfect for financial document analysis and data extraction
LangExtract is a powerful tool for academic research and literature analysis
LangExtract handles both cloud and local models with exceptional performance
Quick Start Guide
Get started with LangExtract in 3 simple steps
1. Define Your Task
Create a prompt and provide examples to guide extraction
import langextract as lx
# Define extraction rules
prompt = "Extract characters and emotions from text"
# Provide a high-quality example
examples = [
lx.data.ExampleData(
text="ROMEO: But soft! What light...",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO"
)
]
)
]2. Run Extraction
Process your text with the defined task
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)3. Visualize Results
Generate interactive HTML visualization
# Save results
lx.io.save_annotated_documents(
[result],
output_name="results.jsonl"
)
# Generate visualization
html_content = lx.visualize("results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)Real-World Use Cases
See LangExtract in action across different domains
Literature Analysis
Extract characters, emotions, and relationships from Romeo and Juliet
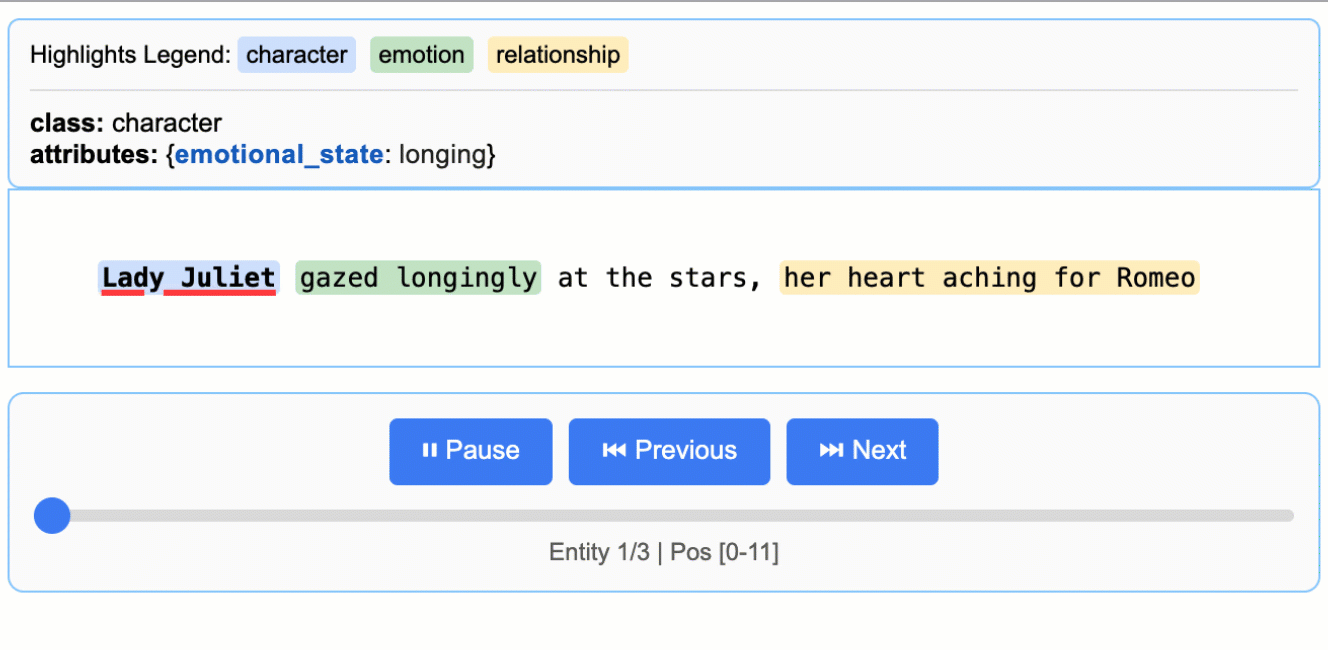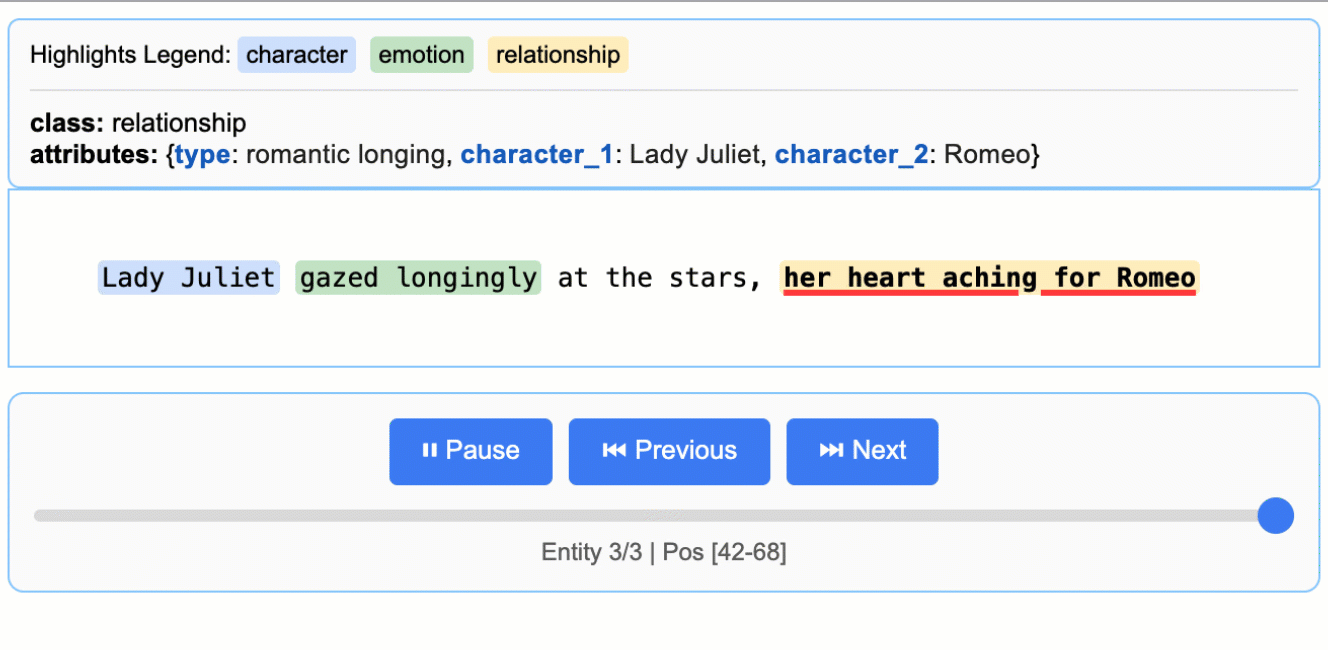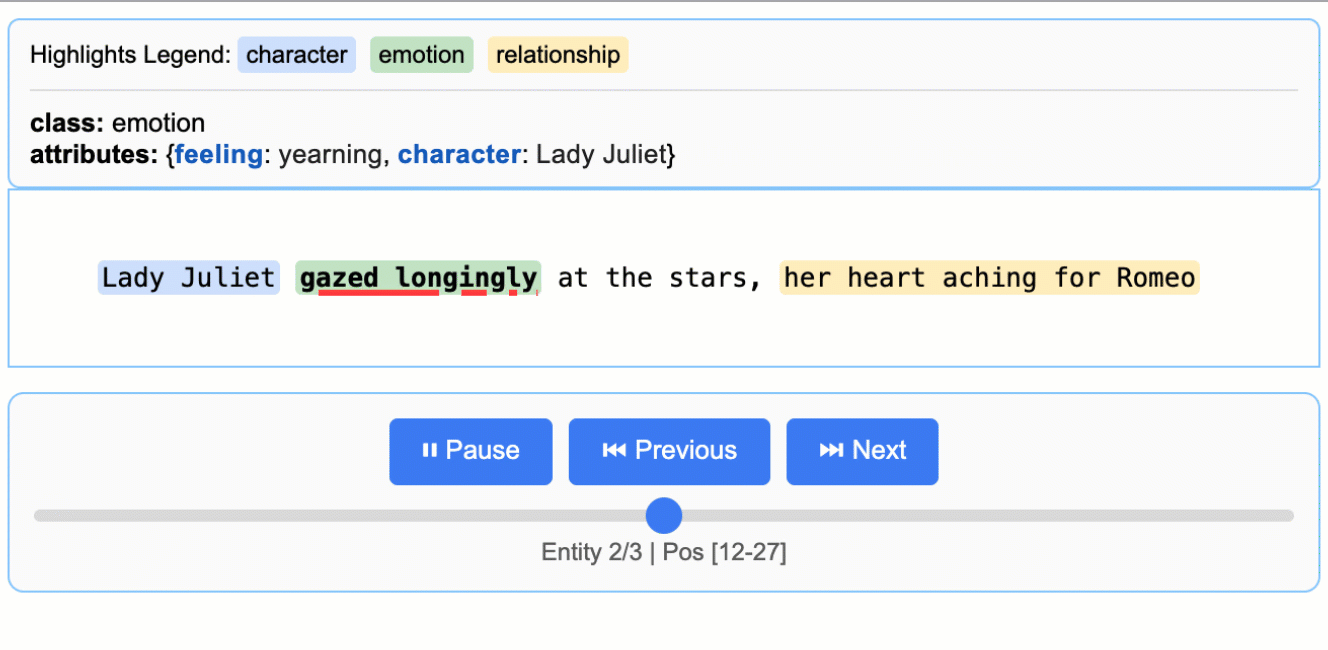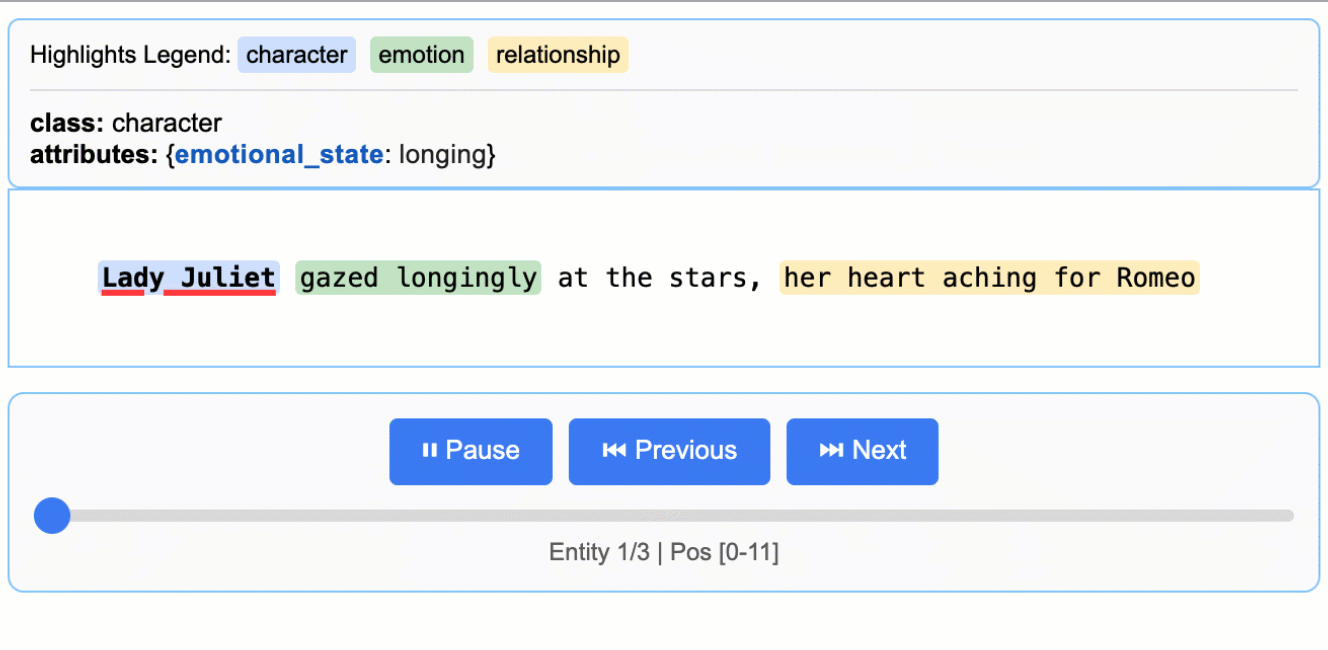
Medical Records
Structure clinical notes and extract medications, dosages, and patient information
RadExtract Demo
Live demo for structuring radiology reports with real-time processing
Installation & Setup
Basic Installation
Development Setup
API Key Setup
For cloud models like Gemini, set up your API key
Ready to Get Started?
Install LangExtract with pip and start extracting structured information from your text data in minutes.