LangExtract
Gemini 驅動的資訊擷取庫
一個使用大語言模型從非結構化文本中擷取結構化資訊的 Python 庫,具備精確的來源定位和互動式視覺化功能。
主要功能
精確來源定位
將每個擷取結果映射到原始文本的確切位置,透過視覺化高亮顯示實現輕鬆追蹤和驗證。
可靠的結構化輸出
基於您的少量範例強制執行一致的輸出架構,利用 Gemini 等支援模型的受控生成功能。
長文檔優化
使用優化的文本分塊、並行處理和多次傳遞,克服"大海撈針"的挑戰,實現更高的召回率。
領域適應性
僅使用少量範例即可為任何領域定義擷取任務。無需微調模型即可適應您的需求。
互動式視覺化
生成互動式 HTML 視覺化,透過直觀的高亮顯示在上下文中檢視擷取的實體。
開源
在 Apache 2.0 許可證下免費使用。社群驅動的開發,完全透明。
應用領域
醫療保健
從臨床記錄和醫療報告中擷取關鍵資訊,同時保持來源可追溯性。
法律文件
從合約和法律文件中擷取條款、日期、當事人和其他資訊。
研究與分析
分析文獻、從學術論文中擷取實體,並結構化無組織的文本數據。
商業智能
將商業文件轉換為結構化數據,用於分析和決策制定。
開發者社群評價
開發者社群對 LangExtract 表現出了極大的興奮和積極回應
AI 透明度與可追溯性
將語言轉化為結構化黃金,具備前所未有的 AI 透明度和可追溯性潛力。
資料科學的未來
資料科學未來的巨大進步,能夠從複雜文檔中擷取結構化資料。
開發者生產力
在所有開發專案中都極其有用,顯著提高工作流程效率。
全球影響力
在全球範圍內受到關注,包括國際開發者社群的強烈興趣。
社群強調的核心優勢
非常適合處理醫療報告和臨床文檔
完美適用於金融文檔分析和資料擷取
學術研究和文獻分析的強大工具
支援雲端和本地模型,效能卓越
快速入門指南
三個步驟開始使用 LangExtract
1. 定義任務
建立引導擷取的提示詞和範例
import langextract as lx
# 定義擷取規則
prompt = "從文本中擷取角色和情感"
# 提供高品質範例
examples = [
lx.data.ExampleData(
text="ROMEO: But soft! What light...",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO"
)
]
)
]2. 執行擷取
使用定義的任務處理文本
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)3. 視覺化結果
生成互動式 HTML 視覺化
# 儲存結果
lx.io.save_annotated_documents(
[result],
output_name="results.jsonl"
)
# 生成視覺化
html_content = lx.visualize("results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)實際應用案例
查看 LangExtract 在各個領域的應用範例
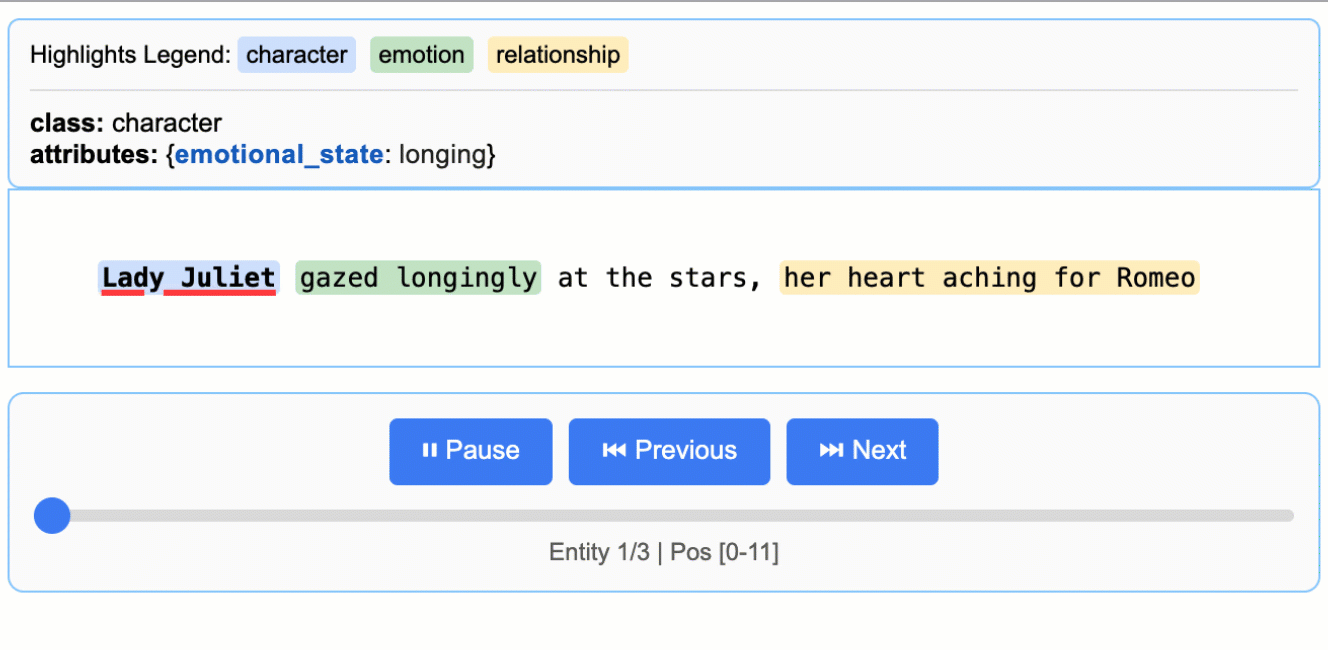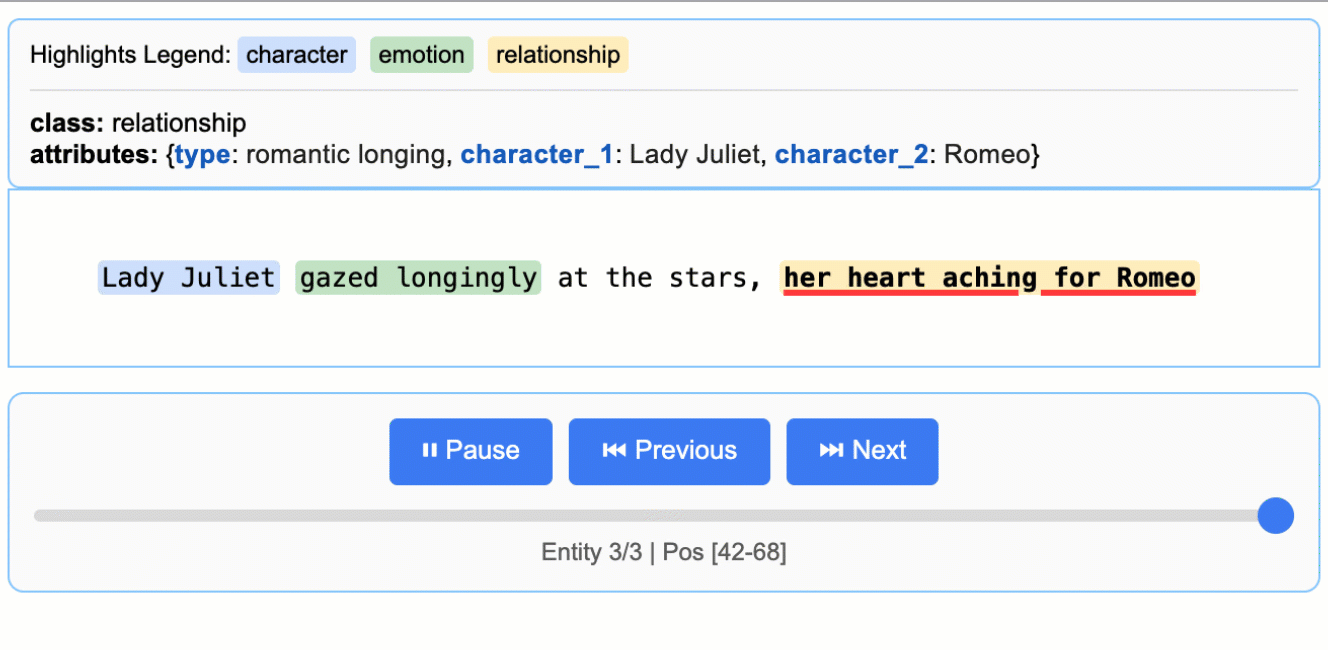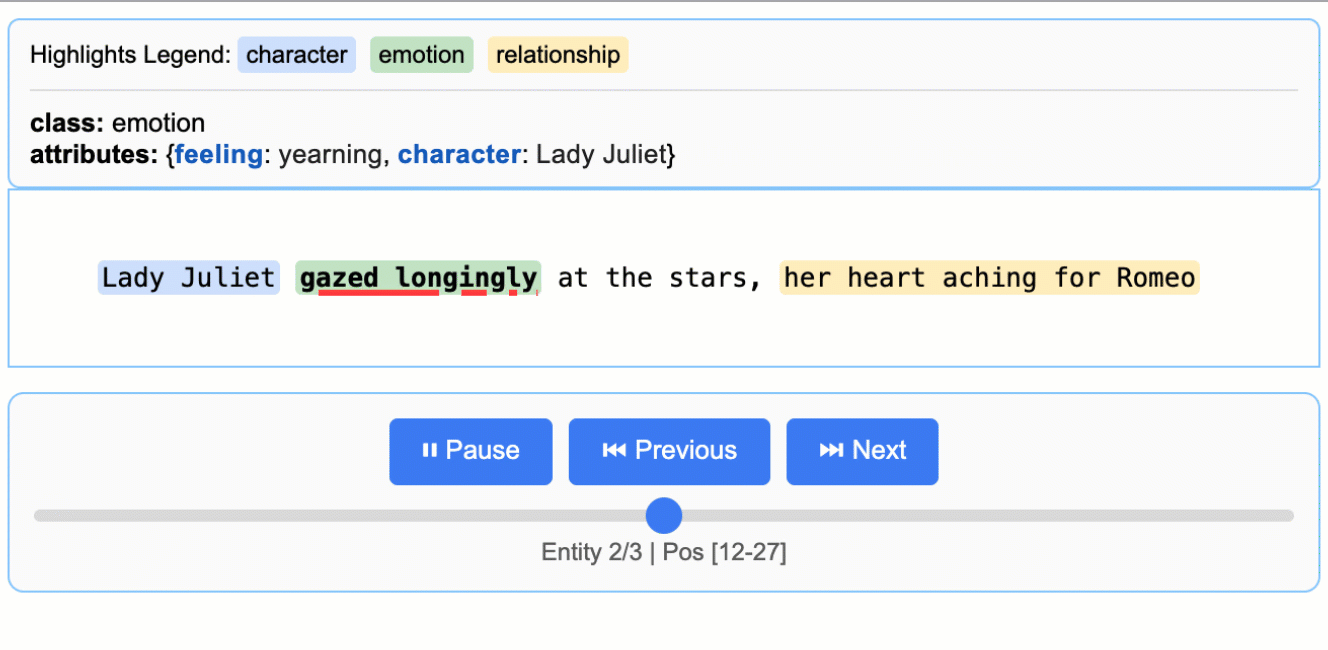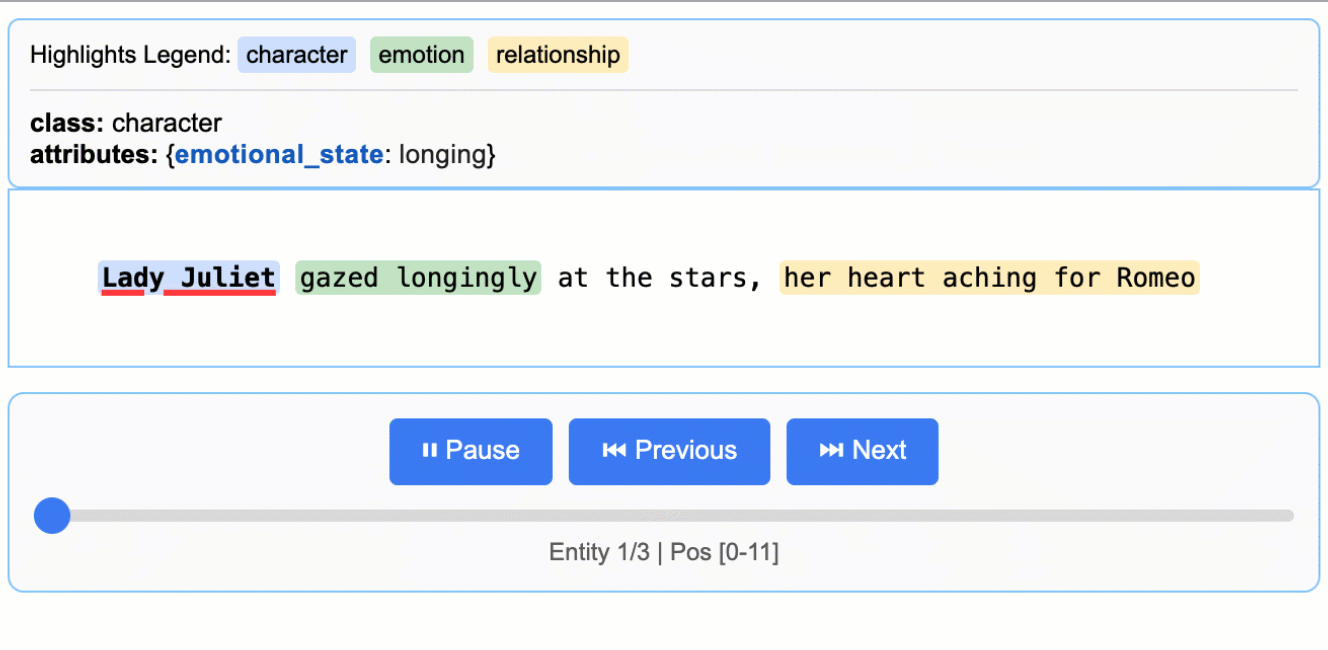
文學分析
從羅密歐與茱麗葉中擷取角色、情感和關係
醫療記錄
結構化臨床記錄並擷取藥物、劑量和患者資訊
RadExtract 演示
即時處理放射線報告結構化的現場演示
安裝與設定
基本安裝
開發環境設定
API 金鑰設定
對於 Gemini 等雲端模型,請設定您的 API 金鑰