LangExtract
Gemini 驱动的信息提取库
一个使用大语言模型从非结构化文本中提取结构化信息的 Python 库,具备精确的源定位和交互式可视化功能。
核心功能
精确源定位
将每个提取结果映射到源文本的确切位置,通过可视化高亮显示实现轻松追踪和验证。
可靠的结构化输出
基于您的少样本示例强制执行一致的输出模式,利用 Gemini 等支持模型的受控生成功能。
长文档优化
使用优化的文本分块、并行处理和多轮传递,克服"大海捞针"的挑战,实现更高的召回率。
领域适应性
仅使用少量示例即可为任何领域定义提取任务。无需微调模型即可适应您的需求。
交互式可视化
生成交互式 HTML 可视化,通过直观的高亮显示在上下文中查看提取的实体。
开源
在 Apache 2.0 许可证下免费使用。社区驱动的开发,完全透明。
应用领域
医疗健康
从临床记录和医疗报告中提取关键信息,同时保持源可追溯性。
法律文档
从合同和法律文件中提取条款、日期、当事人和其他信息。
研究分析
分析文献、从学术论文中提取实体,并结构化无组织的文本数据。
商业智能
将商业文档转换为结构化数据,用于分析和决策制定。
开发者社区评价
开发者社区对 LangExtract 表现出了极大的兴奋和积极响应
AI 透明度与可追溯性
将语言转化为结构化黄金,具备前所未有的 AI 透明度和可追溯性潜力。
数据科学的未来
数据科学未来的巨大进步,能够从复杂文档中提取结构化数据。
开发者生产力
在所有开发项目中都极其有用,显著提高工作流程效率。
全球影响力
在全球范围内受到关注,包括国际开发者社区的强烈兴趣。
社区强调的核心优势
非常适合处理医疗报告和临床文档
完美适用于金融文档分析和数据提取
学术研究和文献分析的强大工具
支持云端和本地模型,性能卓越
快速入门指南
三个步骤开始使用 LangExtract
1. 定义任务
创建引导提取的提示词和示例
import langextract as lx
# 定义提取规则
prompt = "从文本中提取角色和情感"
# 提供高质量示例
examples = [
lx.data.ExampleData(
text="ROMEO: But soft! What light...",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO"
)
]
)
]2. 执行提取
使用定义的任务处理文本
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)3. 可视化结果
生成交互式 HTML 可视化
# 保存结果
lx.io.save_annotated_documents(
[result],
output_name="results.jsonl"
)
# 生成可视化
html_content = lx.visualize("results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)实际应用案例
查看 LangExtract 在各个领域的应用范例
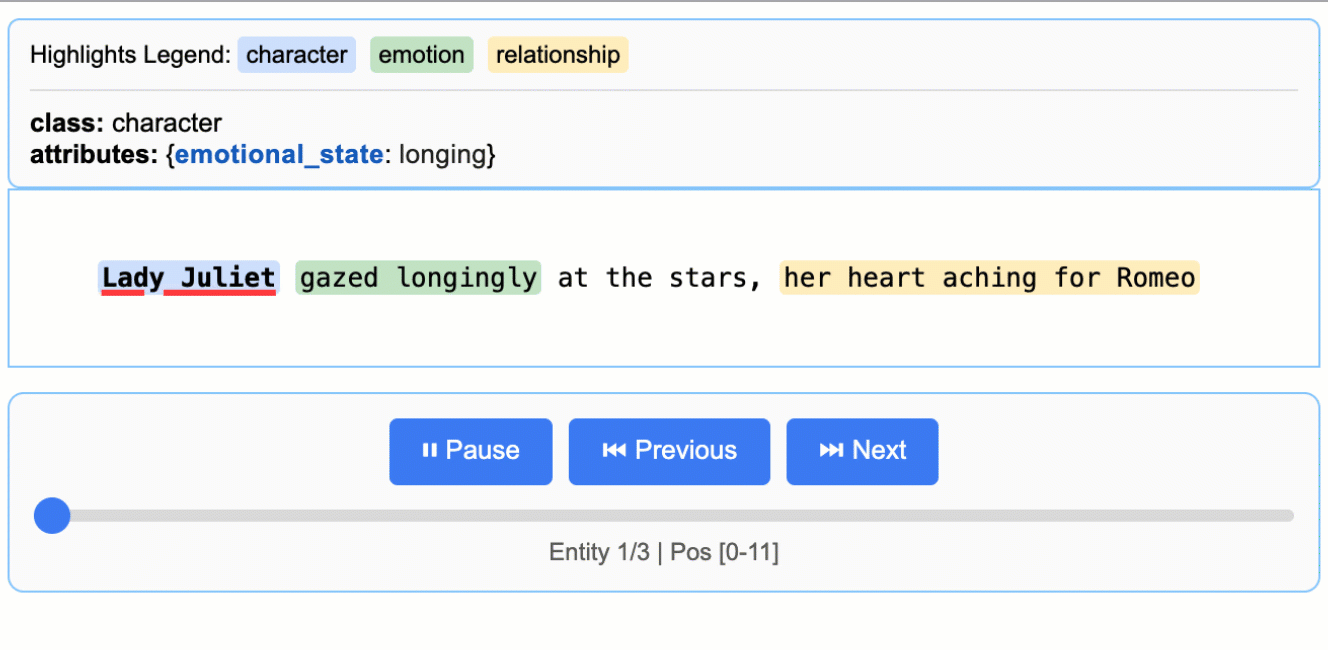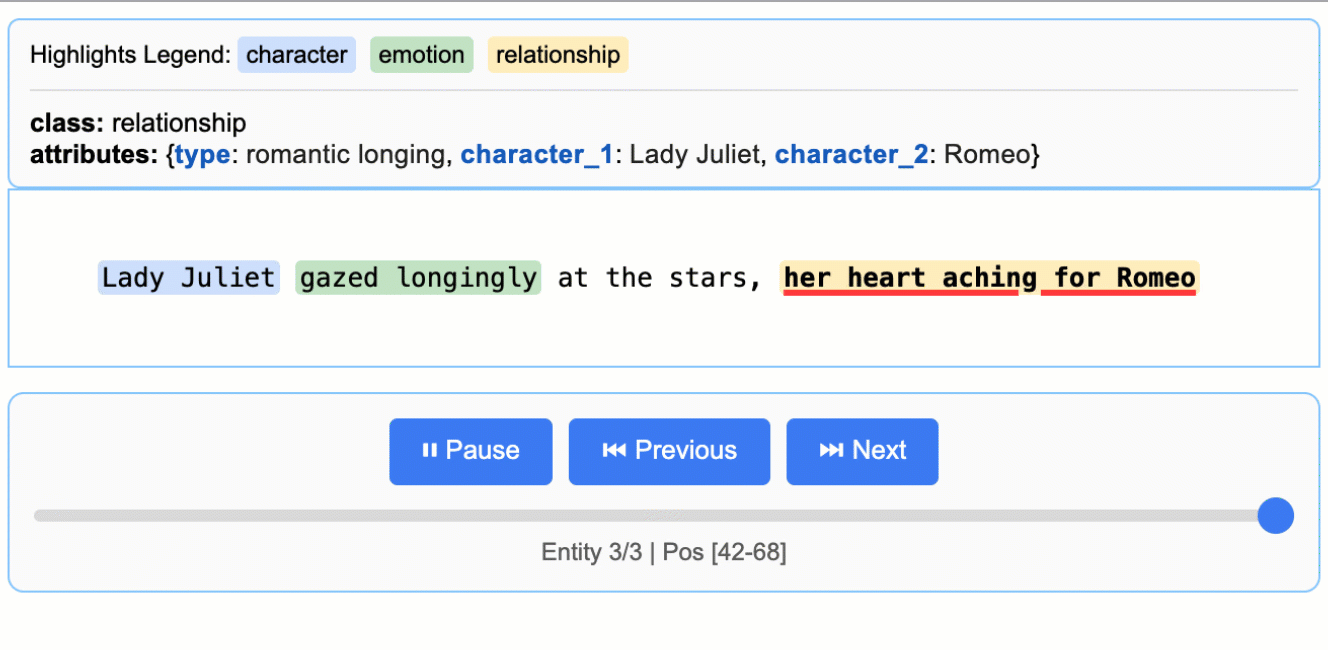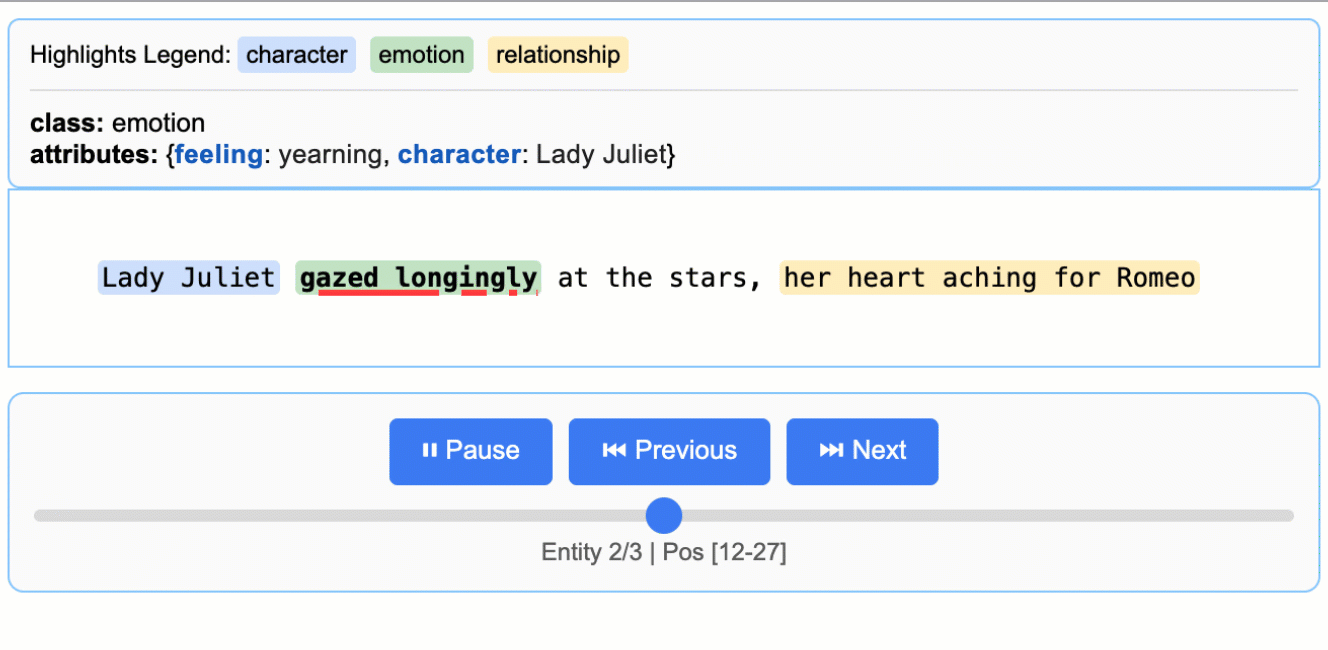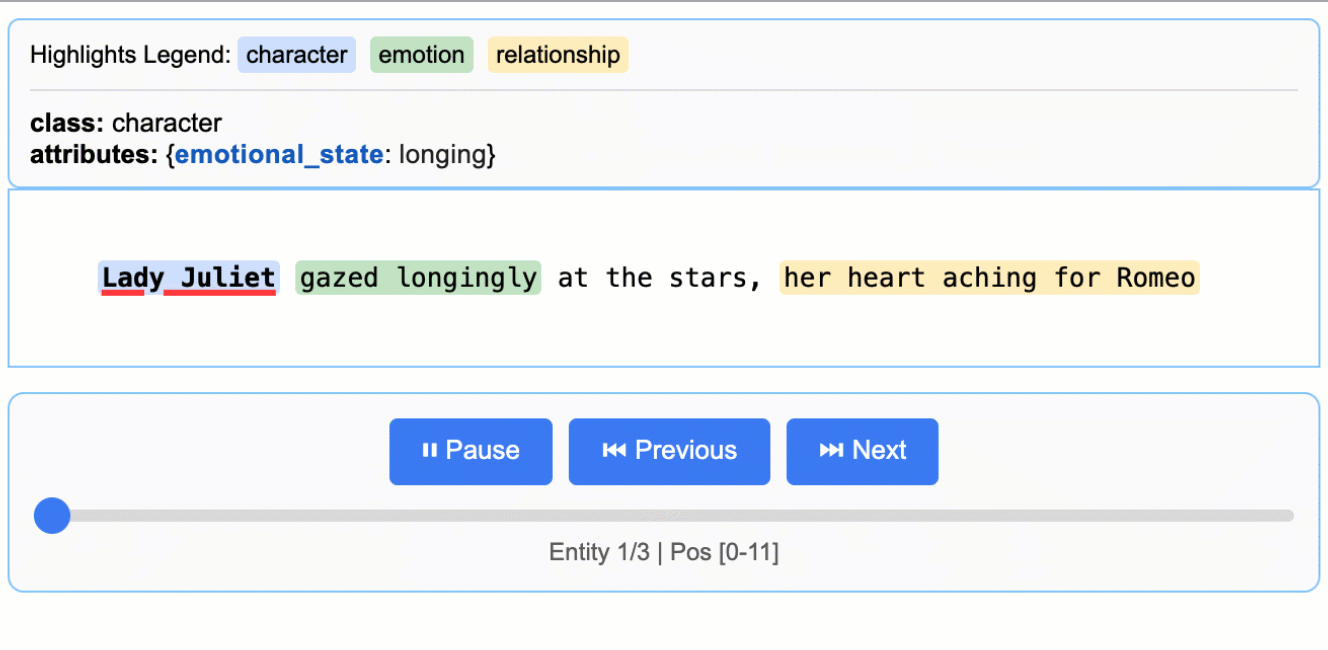
文学分析
从罗密欧与朱丽叶中提取角色、情感和关系
医疗记录
结构化临床记录并提取药物、剂量和患者信息
RadExtract 演示
实时处理放射线报告结构化的现场演示
安装与设置
基本安装
开发环境设置
API 密钥设置
对于 Gemini 等云端模型,请设置您的 API 密钥