LangExtract
Gemini 기반 정보 추출 라이브러리
대규모 언어 모델을 사용하여 비구조화된 텍스트에서 구조화된 정보를 추출하는 Python 라이브러리입니다. 정확한 소스 추적과 대화형 시각화 기능을 제공합니다.
주요 기능
정확한 소스 추적
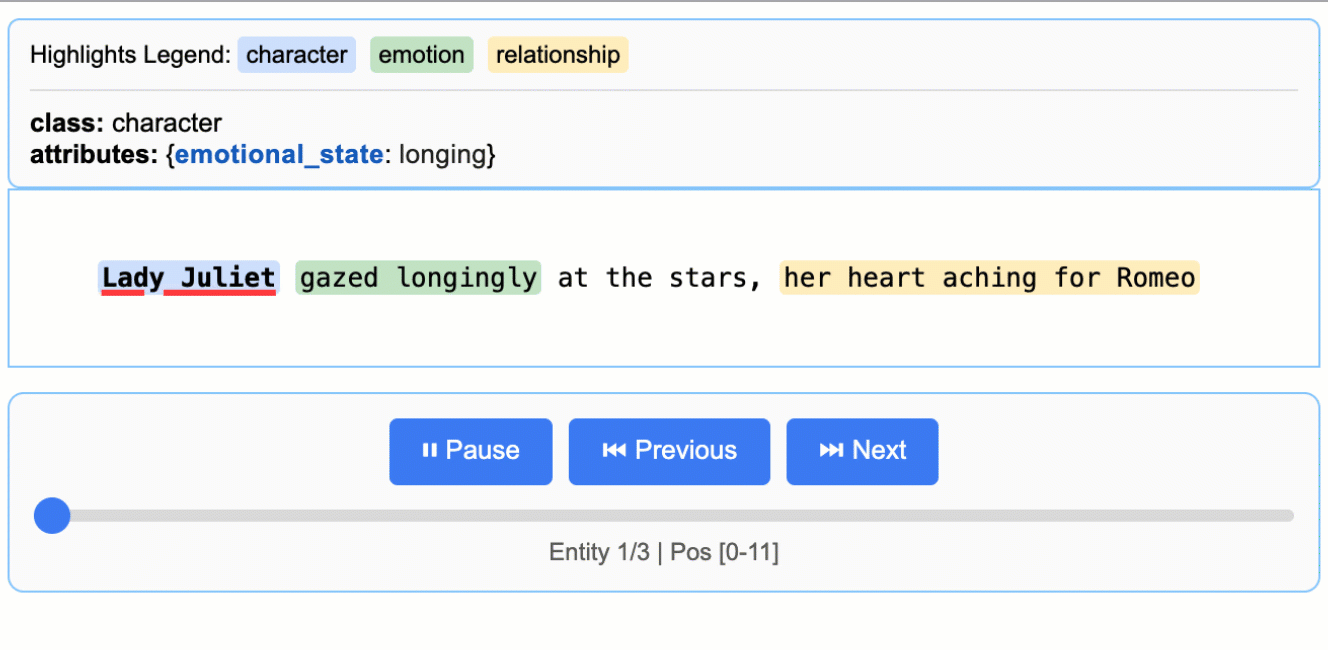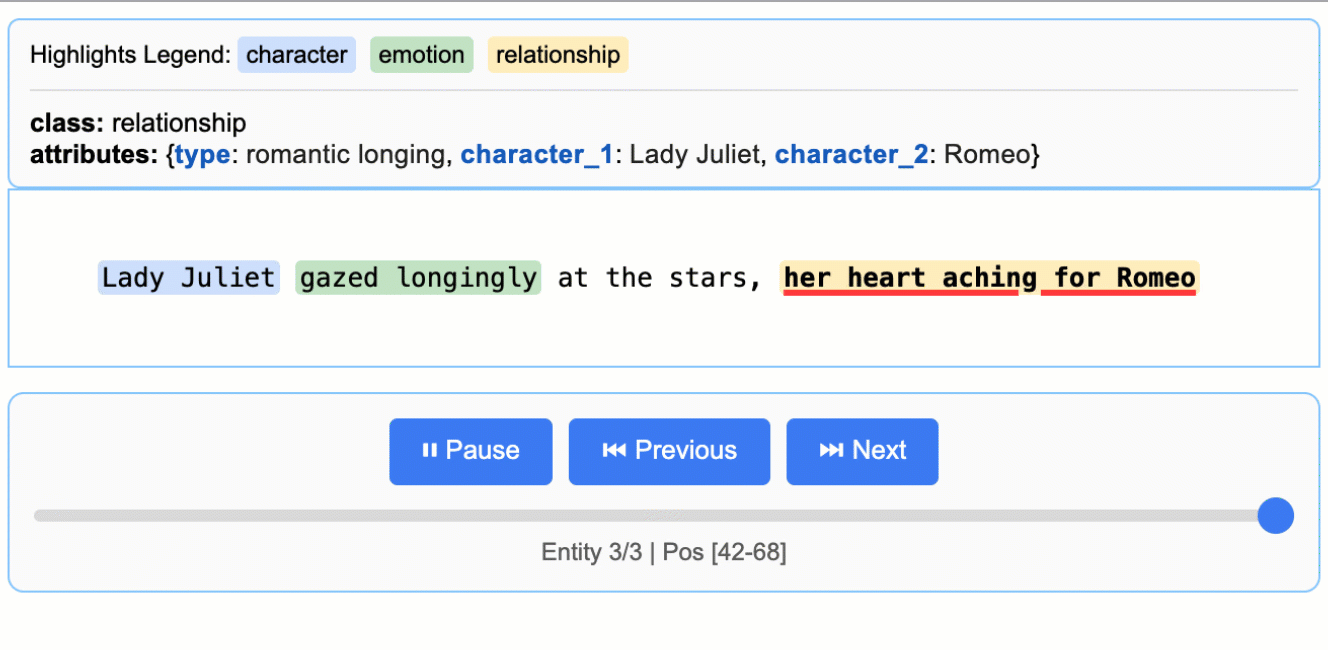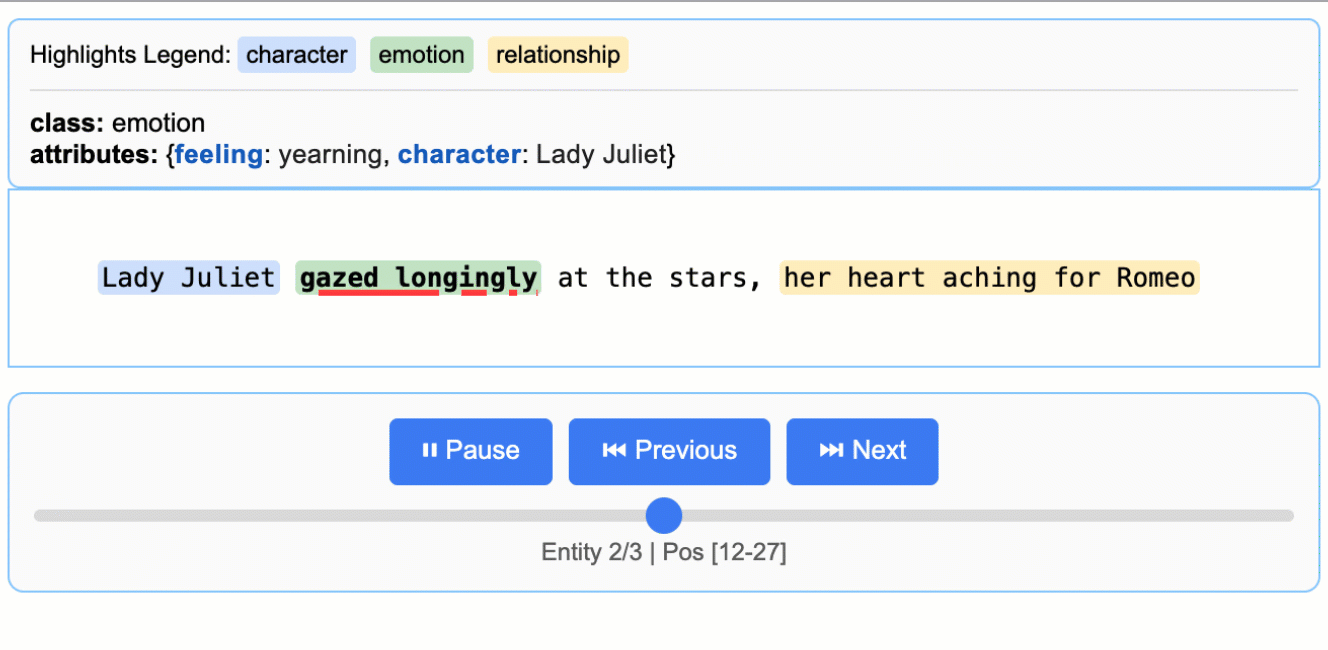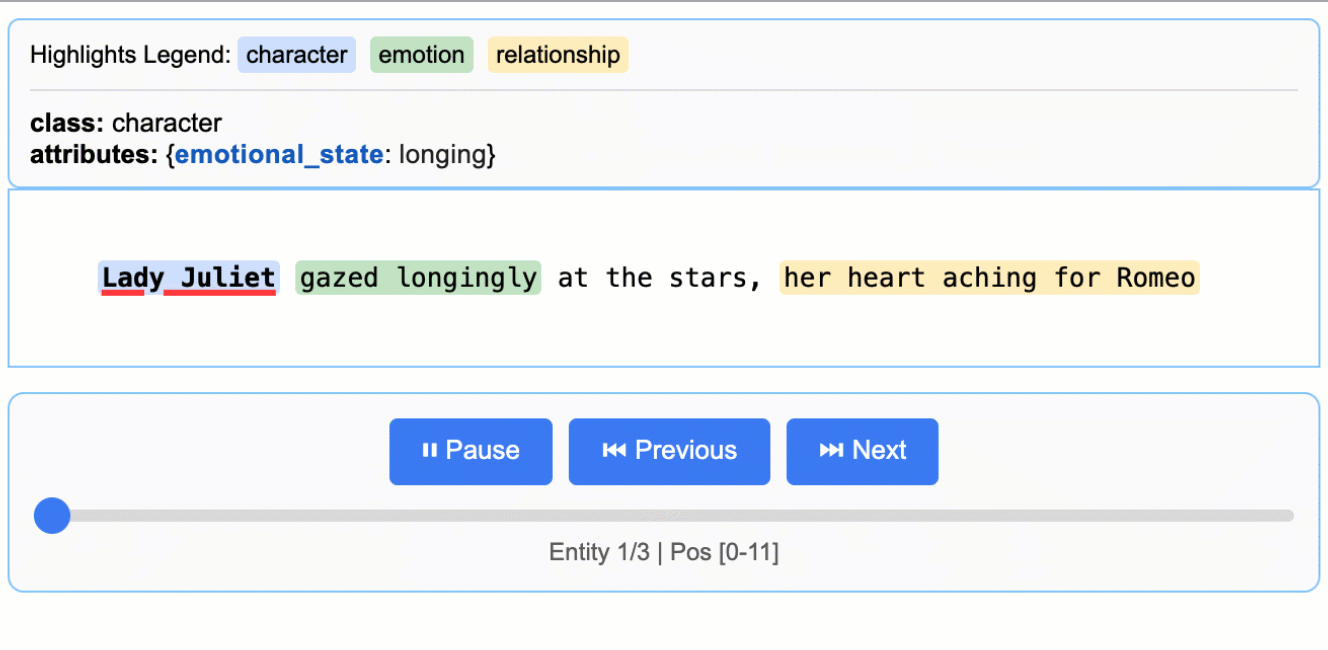
모든 추출 결과를 소스 텍스트의 정확한 위치에 매핑하여 시각적 하이라이트를 통한 쉬운 추적과 검증을 가능하게 합니다.
신뢰할 수 있는 구조화된 출력
소수 샷 예제를 기반으로 일관된 출력 스키마를 강제하며, Gemini와 같은 지원 모델의 제어된 생성을 활용합니다.
긴 문서에 최적화
최적화된 텍스트 청킹, 병렬 처리, 다중 패스를 사용하여 "건초더미에서 바늘 찾기" 문제를 극복하고 더 높은 재현율을 달성합니다.
도메인 적응성
몇 가지 예제만으로 모든 도메인의 추출 작업을 정의할 수 있습니다. 모델 미세 조정 없이도 필요에 맞게 적응합니다.
대화형 시각화
대화형 HTML 시각화를 생성하여 직관적인 하이라이트로 컨텍스트 내에서 추출된 엔티티를 검토할 수 있습니다.
오픈 소스
Apache 2.0 라이선스 하에서 무료로 사용할 수 있습니다. 완전한 투명성을 가진 커뮤니티 주도 개발.
응용 분야
의료
임상 노트와 의료 보고서에서 핵심 정보를 추출하면서 소스 추적 가능성을 유지합니다.
법률 문서
계약서와 법률 문서에서 조항, 날짜, 당사자 및 기타 정보를 추출합니다.
연구 및 분석
문헌을 분석하고, 학술 논문에서 엔티티를 추출하며, 정리되지 않은 텍스트 데이터를 구조화합니다.
비즈니스 인텔리전스
비즈니스 문서를 분석과 의사 결정을 위한 구조화된 데이터로 변환합니다.
개발자 커뮤니티 평가
개발자 커뮤니티는 LangExtract에 대해 엄청난 흥분과 긍정적인 반응을 보이고 있습니다
AI 투명성과 추적 가능성
언어를 구조화된 금으로 변환하며, 전례 없는 AI 투명성과 추적 가능성의 잠재력을 가지고 있습니다.
데이터 사이언스의 미래
데이터 사이언스의 미래를 위한 거대한 진전으로, 복잡한 문서에서 구조화된 데이터를 추출할 수 있습니다.
개발자 생산성
모든 개발 프로젝트에서 매우 유용하며, 워크플로우 효율성을 크게 향상시킵니다.
글로벌 영향력
국제 개발자 커뮤니티의 강한 관심을 포함하여 전 세계적으로 주목받고 있습니다.
커뮤니티가 강조하는 핵심 이점
의료 보고서와 임상 문서 처리에 탁월함
금융 문서 분석과 데이터 추출에 완벽함
학술 연구와 문헌 분석을 위한 강력한 도구
클라우드와 로컬 모델을 모두 뛰어난 성능으로 지원
빠른 시작 가이드
3단계로 LangExtract 시작하기
1. 작업 정의
추출을 안내할 프롬프트와 예제를 생성하세요
import langextract as lx
# 추출 규칙 정의
prompt = "텍스트에서 캐릭터와 감정을 추출"
# 고품질 예제 제공
examples = [
lx.data.ExampleData(
text="ROMEO: But soft! What light...",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO"
)
]
)
]2. 추출 실행
정의된 작업으로 텍스트를 처리하세요
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)3. 결과 시각화
대화형 HTML 시각화를 생성하세요
# 결과 저장
lx.io.save_annotated_documents(
[result],
output_name="results.jsonl"
)
# 시각화 생성
html_content = lx.visualize("results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)실제 사용 사례
다양한 도메인에서 LangExtract 활용 예제 보기
문학 분석
로미오와 줄리엣에서 캐릭터, 감정, 관계 추출
의료 기록
임상 노트를 구조화하고 약물, 복용량, 환자 정보 추출
RadExtract 데모
실시간 처리로 방사선 보고서를 구조화하는 라이브 데모
설치 및 설정
기본 설치
개발 환경 설정
API 키 설정
Gemini와 같은 클라우드 모델의 경우 API 키를 설정하세요
시작할 준비가 되셨나요?
pip로 LangExtract를 설치하고 몇 분 안에 텍스트 데이터에서 구조화된 정보 추출을 시작하세요.