主な機能
正確なソース追跡
すべての抽出結果をソーステキストの正確な位置にマッピングし、視覚的なハイライト表示により簡単な追跡と検証を可能にします。
信頼性の高い構造化出力
少数ショット例に基づいて一貫した出力スキーマを強制し、Geminiなどのサポートされたモデルの制御された生成を活用します。
長文書に最適化
最適化されたテキストチャンキング、並列処理、複数パスを使用して「干し草の山から針を探す」課題を克服し、より高いリコールを実現します。
ドメイン適応性
わずかな例を使用してあらゆるドメインの抽出タスクを定義できます。モデルの微調整を必要とせずにニーズに適応します。
インタラクティブな可視化
インタラクティブなHTML可視化を生成し、直感的なハイライト表示でコンテキスト内の抽出エンティティをレビューできます。
オープンソース
Apache 2.0ライセンスの下で無料で使用できます。完全な透明性を持つコミュニティ主導の開発。
応用分野
ヘルスケア
臨床ノートや医療レポートから重要な情報を抽出し、ソースの追跡可能性を維持します。
法的文書
契約書や法的文書から条項、日付、当事者、その他の情報を抽出します。
研究・分析
文献を分析し、学術論文からエンティティを抽出し、未整理のテキストデータを構造化します。
ビジネスインテリジェンス
ビジネス文書を構造化データに変換し、分析と意思決定に活用します。
開発者コミュニティの声
開発者コミュニティはLangExtractに対して非常に興奮し、積極的な反応を示しています
AIの透明性と追跡可能性
言語を構造化されたゴールドに変換し、前例のないAIの透明性と追跡可能性の可能性を持っています。
データサイエンスの未来
データサイエンスの未来にとって大きな前進であり、複雑な文書から構造化データを抽出できます。
開発者の生産性
すべての開発プロジェクトで非常に有用であり、ワークフローの効率を大幅に向上させます。
グローバルな影響
国際的な開発者コミュニティからの強い関心を含め、世界中で注目を集めています。
コミュニティが強調する主要な利点
医療レポートや臨床文書の処理に最適
金融文書分析とデータ抽出に完璧
学術研究と文献分析のための強力なツール
クラウドとローカルモデルの両方を優れた性能でサポート
クイックスタートガイド
3ステップでLangExtractを始める
1. タスクを定義
抽出をガイドするプロンプトと例を作成します
import langextract as lx
# 抽出ルールを定義
prompt = "テキストからキャラクターと感情を抽出"
# 高品質な例を提供
examples = [
lx.data.ExampleData(
text="ROMEO: But soft! What light...",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO"
)
]
)
]2. 抽出を実行
定義されたタスクでテキストを処理します
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)3. 結果を可視化
インタラクティブなHTML可視化を生成します
# 結果を保存
lx.io.save_annotated_documents(
[result],
output_name="results.jsonl"
)
# 可視化を生成
html_content = lx.visualize("results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)実際の使用例
さまざまなドメインでのLangExtractの活用例を見る
文学分析
ロミオとジュリエットからキャラクター、感情、関係を抽出(147,843文字)
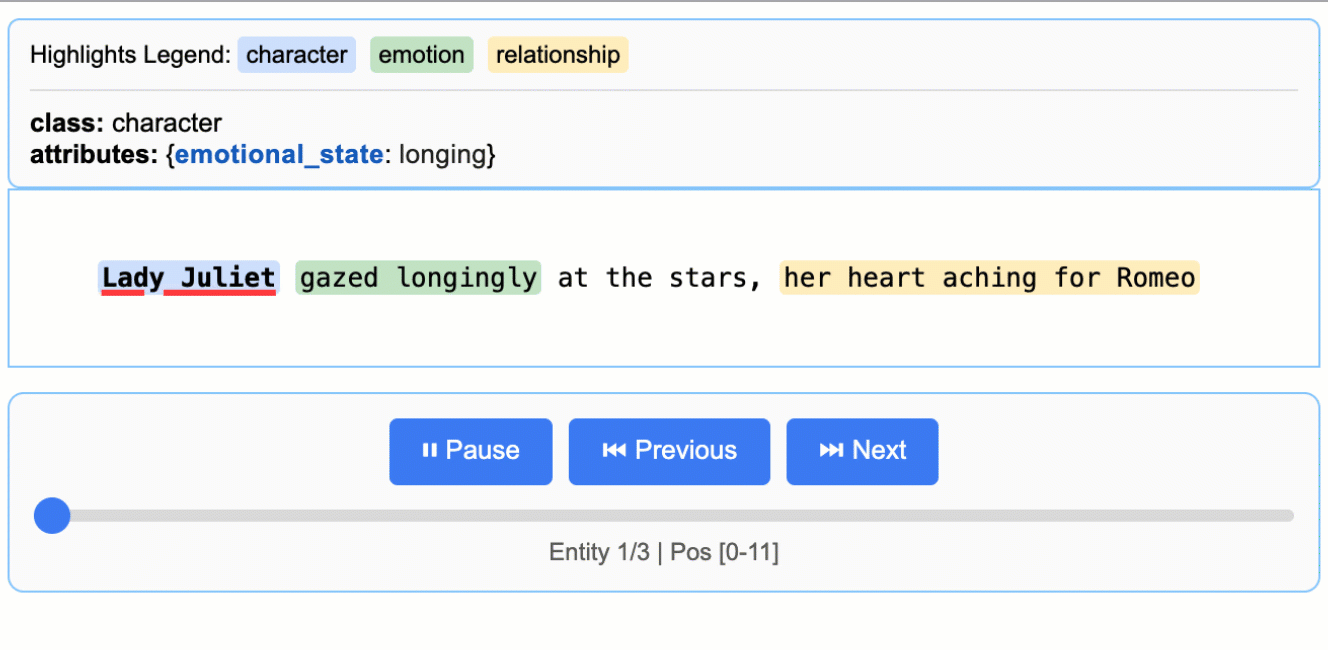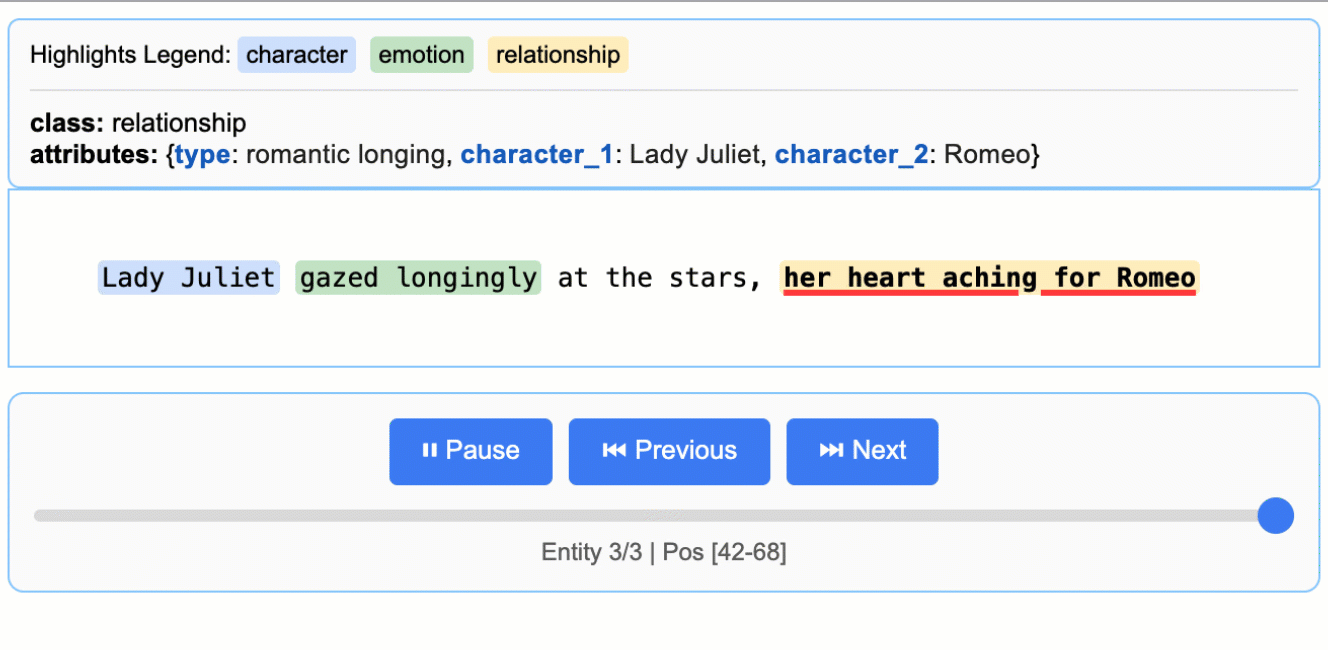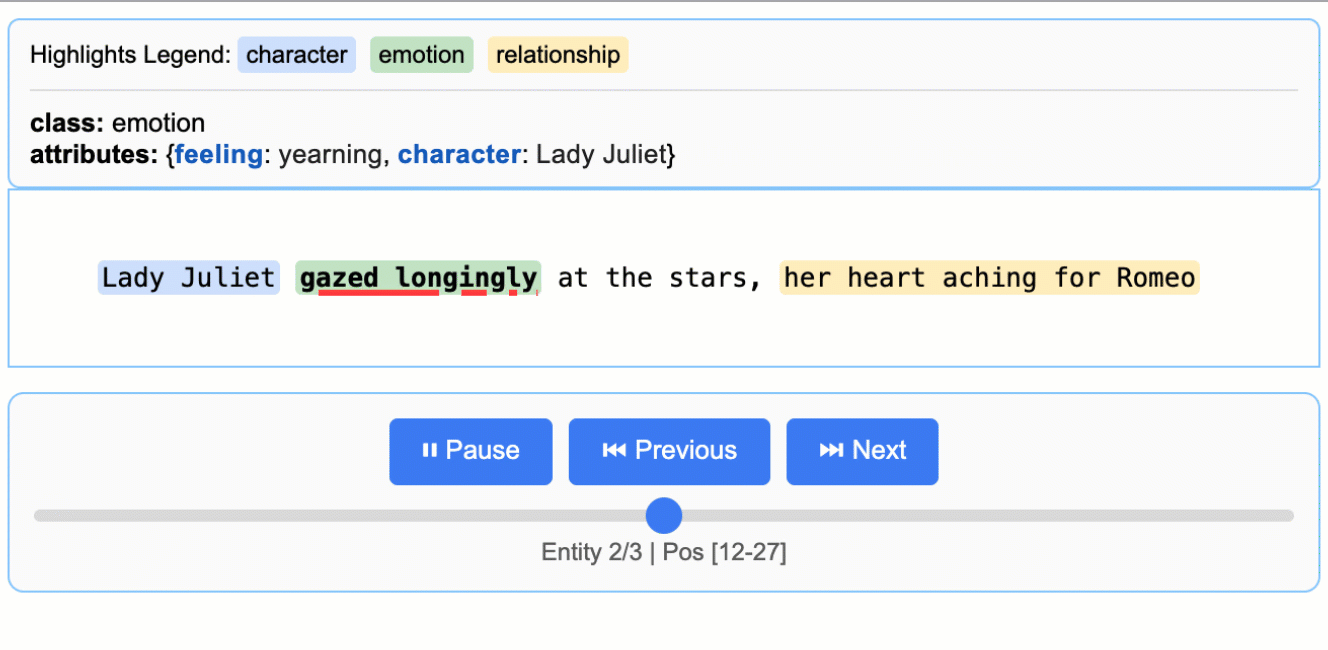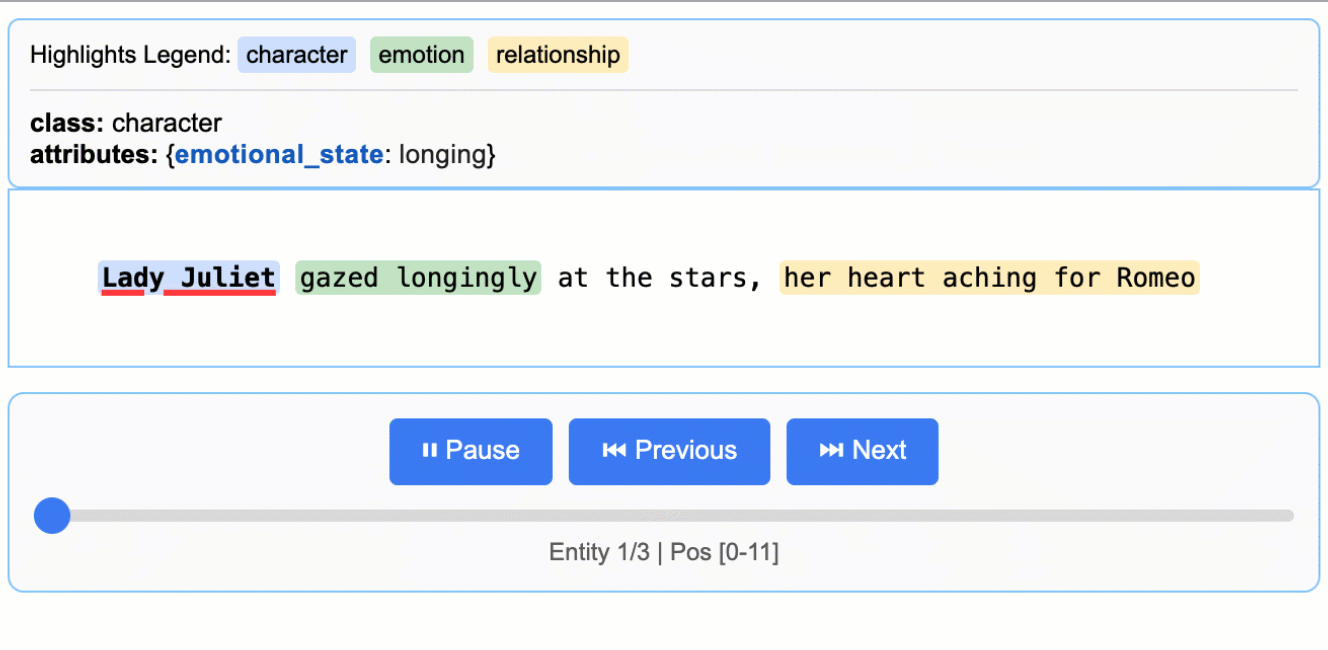
医療記録
臨床ノートを構造化し、薬物、用量、患者情報を抽出
RadExtractデモ
リアルタイム処理で放射線レポートを構造化するライブデモ
インストールとセットアップ
基本インストール
開発環境セットアップ
APIキーの設定
Geminiなどのクラウドモデルの場合、APIキーを設定してください